Web scraping: Parsing Tables

When working on projects, some times I bet you wonder where the raw data comes from. They could be gotten through various means, data entry, web scraping and APIs etc.
In this post, I'll be explaining how to scrape tables from websites with simple blocks of python code on Jupyter notebook.
I encountered various ways to extract data from tables while tackling a challenge. I believe this would be useful to others who have this same struggle. This is the easier method and requires little or no knowledge of HTML.
To make sure we are not illegally scraping a website we would be scrapping a table from an open website. We would use the libraries, requests and pandas to extract the values and load them into a csv file.

Import the libraries or modules required
import requests
import pandas as pd
Next, I have defined a function that gets the content of the entire webpage, I put this in a function because I do a lot of web scraping. If you use a block of code quite often consider making it a function, it saves time and errors from copying and pasting.
def get_url(url):
response = requests.get(url).content
return response
Then we, store the webpage content in the variable "site"
url = "https://countrycode.org/"
site = get_url(URL)
Finally, Pandas extracts the table into a list(s) and stores it in the variable "table" which is converted to a data frame to be loaded into a csv file.
table = pd.read_html(site)
table_df = pd.DataFrame(table[-2]) # The indexing is used to find the list that contains all the datafields we require
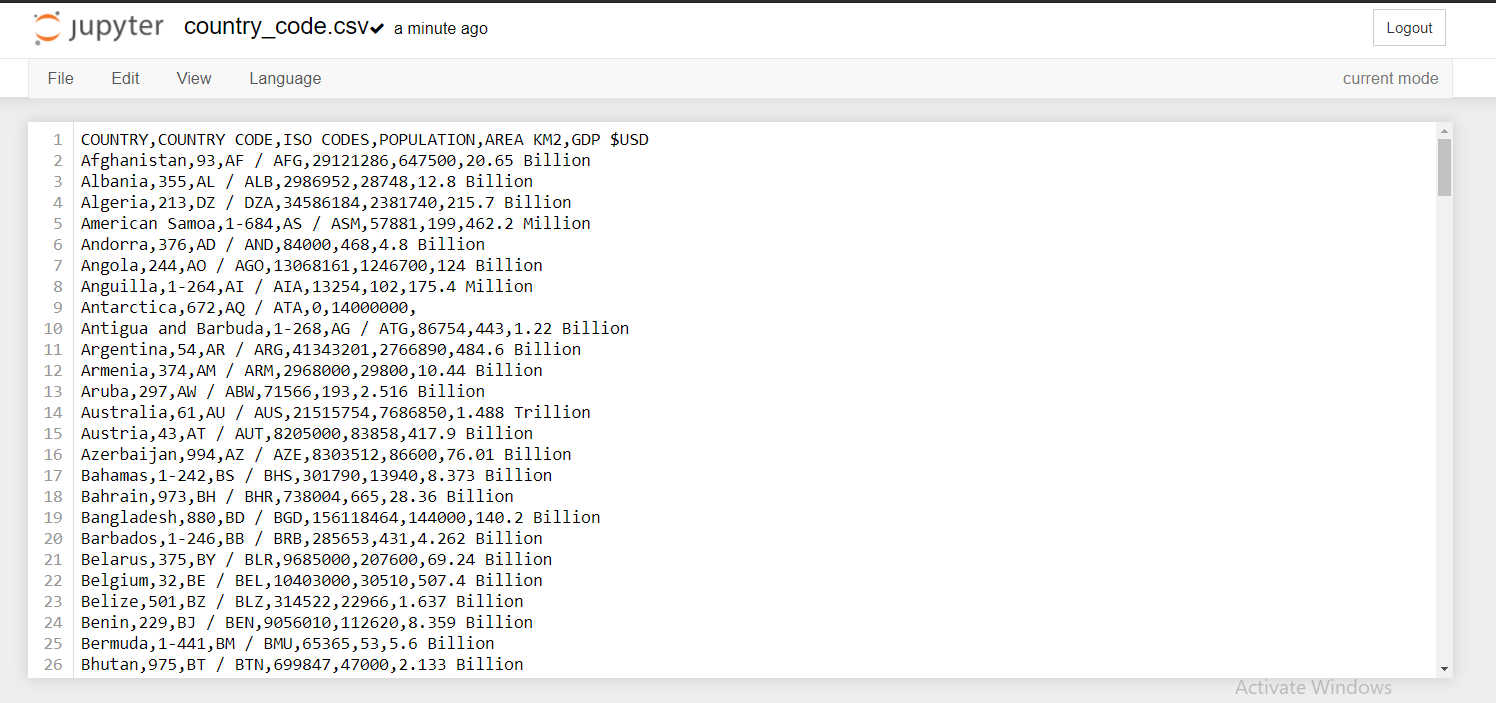
table_df.to_csv("country_code.csv",index=False)
Voila!, Here's our data stored in a csv file ready to be put to work.